概述
- 硬件:针对第一期demo硬件,x99+16G+v100x2 32G
- 引擎:llama.cpp
- 应用:open-webui对话、opencode项目任务
- 基本概念
- 显存 (VRAM) 带宽:约 900 GB/s (V100 SXM2)。
- 物理内存 (RAM) 带宽:约 50-60 GB/s (DDR4 四通道)。
- 固态硬盘 (SSD) 写入/读取:约 3-7 GB/s (PCIe 3.0/4.0)。
调试步骤
设置参数启动模型
llama-server --port 8080 -m ~/storage/GGUF/Huihui-Qwen3.5-27B-Claude-4.6-Opus-abliterated-Q4_K_M.gguf --host 0.0.0.0 --ctx-size 153600 --n-gpu-layers 99 --tensor-split 1,1 --flash-attn on --cache-type-k q4_0 --cache-type-v q4_0 --parallel 3 --threads 12 --batch-size 512 --ubatch-size 512 --temp 0.3 --min-p 0.05 --repeat-penalty 1.1 --timeout 1200 --api-key xxxxxxxxx- frpc重新运行穿透,openai重新运行
chat对话输入任务,观察
- 应用端的计算结果
- 服务端的槽位处理情况
- 服务端nvitop观察内存和显存
怎么制造Cfourbombopencode输入任务,观察
- 任务处理过程,是否详尽
- 服务端的槽位处理情况
- 服务端nvitop观察内存和显存
- 生成的产物文件内容是否准确
分析优化continue手册,达到用户拿到手册阅读可以很直观理解continue,并按照手册的操作步骤可以完成continue部署,最后在本地电脑复现一个continue代码补全实例 分析选型一个vscode插件,适合接入已有的llama.cpp带apikey的私有化代码补全开发。选择之后需要设计一份该插件的操作手册,达到用户拿到手册阅读可以很直观理解该插件工作机制,并按照手册的操作步骤可以完成部署安装,最后在本地电脑复现一个该插件的代码补全实例- 根据剩余的显存和内存,增加上下文/槽位/批次长度
观测手段
资源
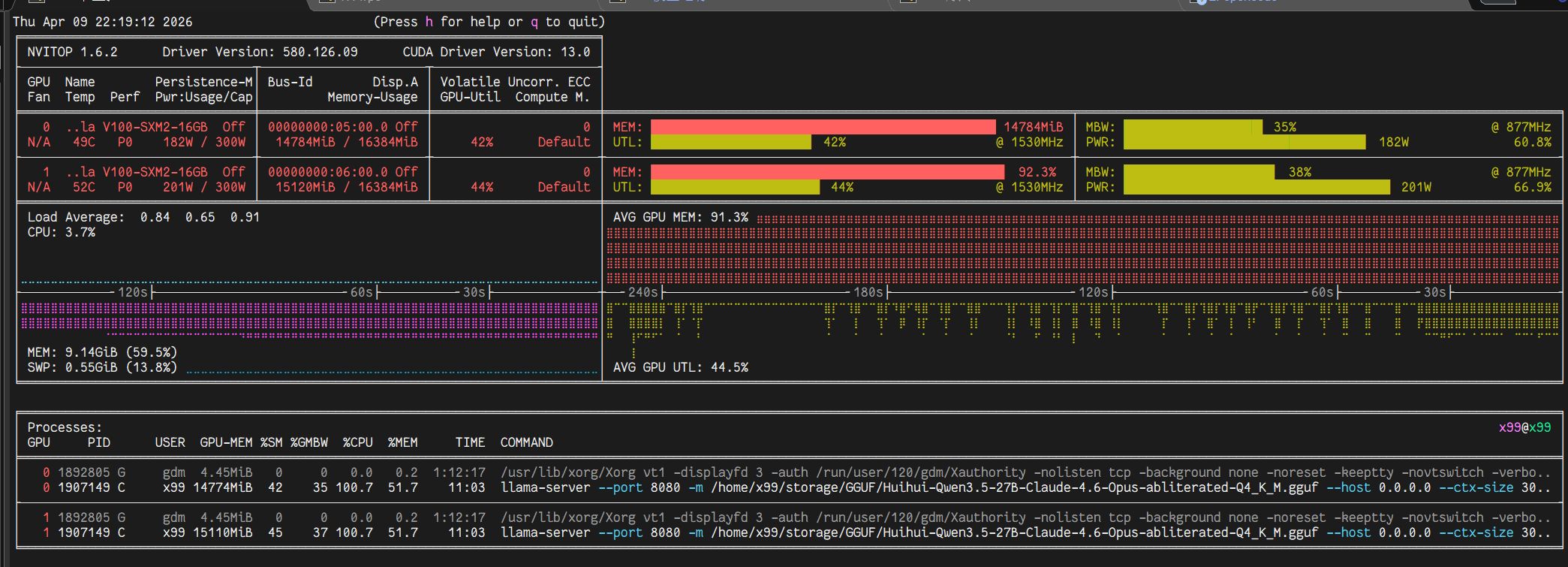
服务信息
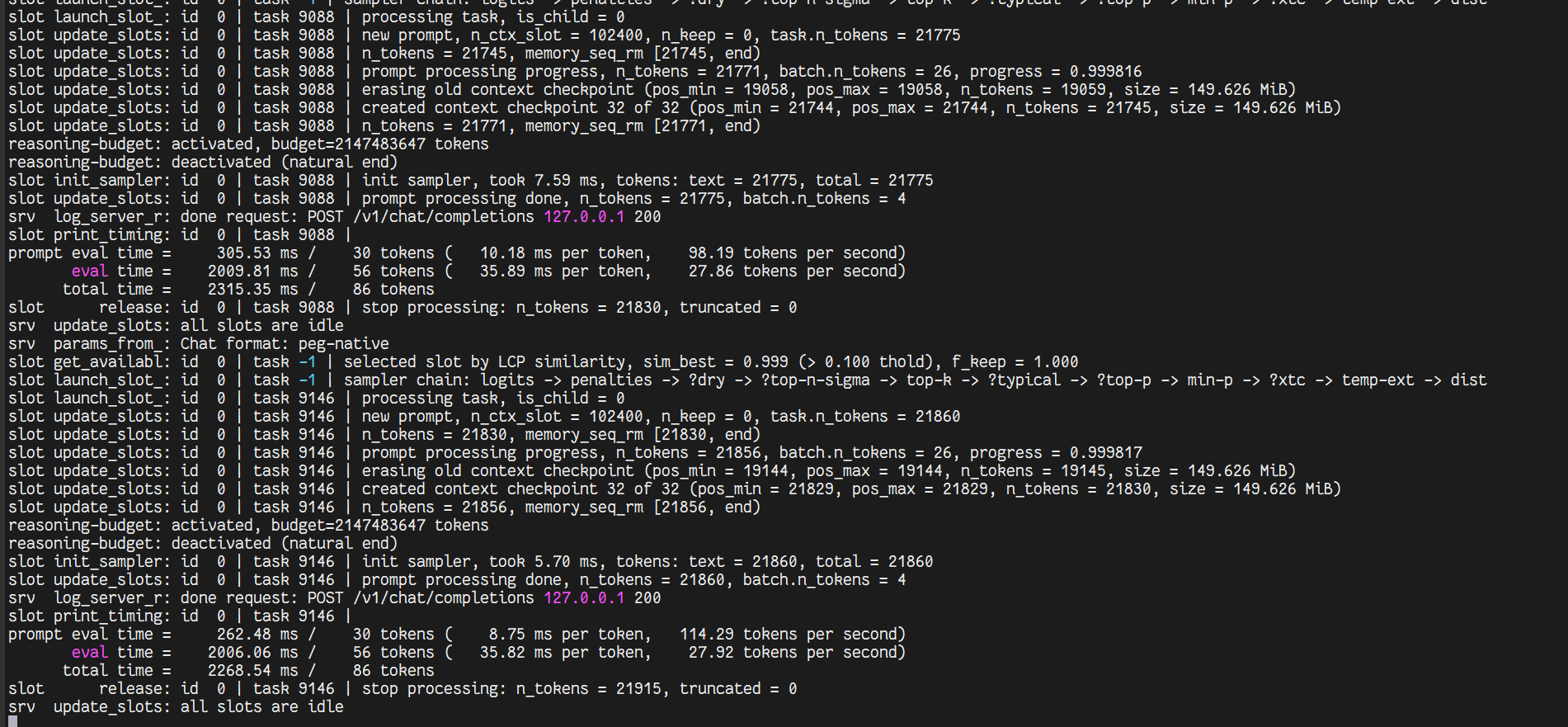
显存崩爆

本地算力穿透

结论
- 加载完模型,显存的危险线70%
- 并发用户数=槽位
- 批次按着内存来,opencode长任务70%内安全