https://evalscope.readthedocs.io/zh-cn/latest/index.html
快速开始
# 安装
pip install evalscope[perf] -U
# 压测
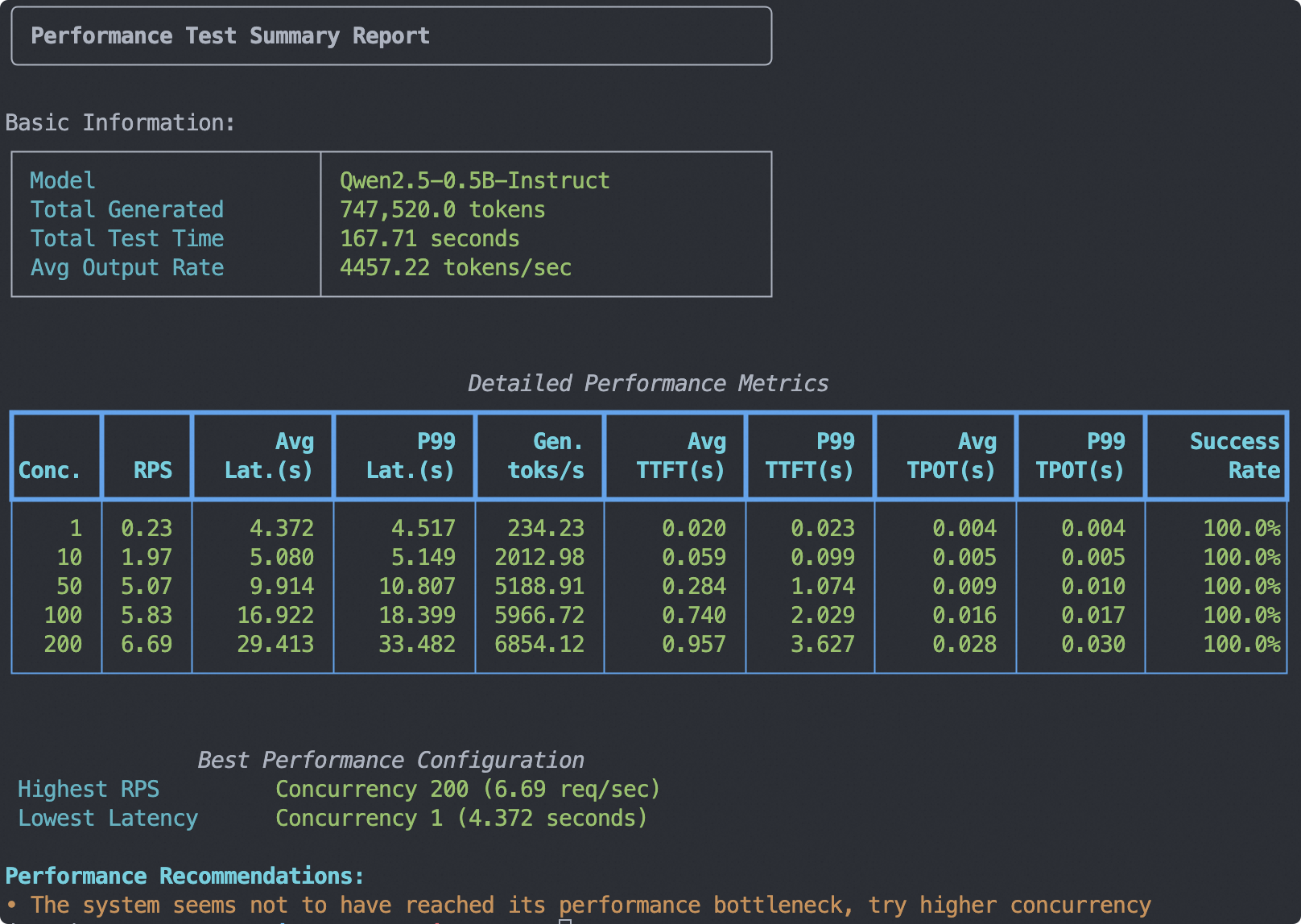
evalscope perf \
--parallel 1 10 50 100 200 \
--number 10 20 100 200 400 \
--model Qwen2.5-0.5B-Instruct \
--url http://127.0.0.1:8801/v1/chat/completions \
--api openai \
--api-key xxxx\
--dataset random \
--max-tokens 1024 \
--min-tokens 1024 \
--prefix-length 0 \
--min-prompt-length 1024 \
--max-prompt-length 1024 \
--tokenizer-path Qwen/Qwen2.5-0.5B-Instruct \
--extra-args '{"ignore_eos": true}'
参数说明
基本设置
| 参数 | 类型 | 说明 | 默认值 |
|---|
--model | str | 测试模型名称,或模型路径 | - |
--url | str | API地址,支持/chat/completion和/completion端点 | - |
--name | str | wandb/swanlab数据库结果名称和结果数据库名称 | {model_name}_{current_time} |
--api | str | 服务API类型 • openai: OpenAI兼容API(需提供--url) • openai_embedding: OpenAI兼容Embedding API • openai_rerank: OpenAI/Cohere兼容Rerank API • local: 启动本地transformers推理 • local_vllm: 启动本地vLLM推理服务 • 自定义:参考自定义API指南 | - |
--port | int | 本地推理服务端口 仅对local和local_vllm有效 | 8877 |
--attn-implementation | str | Attention实现方式 仅在api=local时有效 | None (可选:flash_attention_2、eager、sdpa) |
--api-key | str | API密钥 | None |
--debug | bool | 是否输出调试信息 | False |
网络配置
| 参数 | 类型 | 说明 | 默认值 |
|---|
--total-timeout | int | 每个请求的总超时时间(秒) | 21600(6小时) |
--connect-timeout | int | 网络连接超时(秒) | None |
--read-timeout | int | 网络读取超时(秒) | None |
--headers | str | 额外的HTTP头 格式:key1=value1 key2=value2 将用于每个查询 | - |
--no-test-connection | bool | 不发送连接测试,直接开始压测 | False |
请求控制
| 参数 | 类型 | 说明 | 默认值 |
|---|
--parallel | list[int] | 并发请求的数量 可传入多个值,空格分隔 | 1 |
--number | list[int] | 发出的请求总数量 可传入多个值(需与parallel一一对应) | 1000 |
--rate | float | 请求生成速率(请求/秒) • -1: 请求不限速,立即全部生成并放入队列 • > 0: 请求按泊松到达模型生成,生成间隔服从均值为 1/rate 的指数分布,即平均每秒生成 rate 个请求 | -1 |
--log-every-n-query | int | 每N个查询记录日志 | 10 |
--stream | bool | 是否使用SSE流输出 需要启用以测量TTFT(Time to First Token)指标 | True |
--sleep-interval | int | 每次性能测试之间的休眠时间(秒) 避免过载服务器 | 5 |
小技巧
--rate 与 --parallel 控制的是两个独立阶段:
两个参数相互独立:rate 决定请求以多快的节奏送进队列,parallel 决定同时有多少个请求处于发送状态。
SLA设置
| 参数 | 类型 | 说明 | 默认值 |
|---|
--sla-auto-tune | bool | 是否启用SLA自动调优模式 | False |
--sla-variable | str | 自动调优的变量 可选:parallel(并发数)、rate(请求速率) | parallel |
--sla-params | str | SLA约束条件 JSON字符串 支持指标:avg_latency, p99_latency, avg_ttft, p99_ttft, avg_tpot, p99_tpot, rps, tps 支持操作符:<=, <, min (延时类); >=, >, max (吞吐类) 示例:'[{"p99_latency": "<=2"}]' | None |
--sla-upper-bound | int | 被调优变量的搜索上界 | 65536 |
--sla-lower-bound | int | 被调优变量的搜索下界 | 1 |
--sla-fixed-parallel | int | 在 --sla-variable=rate 时使用的固定并发数;未设置时默认回退到 --sla-upper-bound 以兼容旧行为 | None |
--sla-num-runs | int | 每个并发级别的运行次数(取平均值) | 3 |
--sla-number-multiplier | float | 每次测试时请求总数相对于被调优变量(并发数或速率)的倍数,即 number = round(variable × N);未设置时默认为 2 | None |
参见
SLA自动调优功能使用详见自动调优指南。
Prompt设置
| 参数 | 类型 | 说明 | 默认值 |
|---|
--max-prompt-length | int | 最大输入prompt长度 超过该值时将丢弃prompt | 131072 |
--min-prompt-length | int | 最小输入prompt长度 小于该值时将丢弃prompt | 0 |
--prefix-length | int | prompt的前缀长度 仅对random数据集有效 | 0 |
--prompt | str | 指定请求prompt 字符串或本地文件(通过@/path/to/file指定) 优先级高于dataset 示例:@./prompt.txt | - |
--query-template | str | 指定查询模板 JSON字符串或本地文件(通过@/path/to/file指定) 示例:@./query_template.json | - |
--apply-chat-template | bool | 是否应用聊天模板 | None(根据URL后缀自动判断) |
--image-width | int | 随机VL数据集图像宽度 | 224 |
--image-height | int | 随机VL数据集图像高度 | 224 |
--image-format | str | 随机VL数据集图像格式 | RGB |
--image-num | int | 随机VL数据集图像数量 | 1 |
--image-patch-size | int | 图像的patch大小 仅用于本地图像token计算 | 28 |
数据集配置
| 参数 | 类型 | 说明 | 默认值 |
|---|
--dataset | str | 数据集模式,详见下表 | - |
--dataset-path | str | 数据集文件路径 与数据集结合使用 | - |
dataset 模式说明
| 模式 | 说明 | 支持dataset-path |
|---|
openqa | 从ModelScope自动下载OpenQA prompt长度较短(一般<100 token) 指定dataset_path时使用jsonl文件的question字段 | ✓ |
longalpaca | 从ModelScope自动下载LongAlpaca-12k prompt长度较长(一般>6000 token) 指定dataset_path时使用jsonl文件的instruction字段 | ✓ |
line_by_line | 逐行将txt文件的每一行作为一个prompt 必需提供dataset_path | ✓(必需) |
flickr8k | 从ModelScope自动下载Flick8k 构建图文输入,数据集较大,适合评测多模态模型 | ✗ |
kontext_bench | 从ModelScope自动下载Kontext-Bench 构建图文输入,约1000条数据,适合快速评测多模态模型 | ✗ |
random | 根据prefix-length、max-prompt-length和min-prompt-length随机生成prompt 必需指定tokenizer-path 使用示例 | ✗ |
random_vl | 随机生成图像和文本输入 在random基础上增加图像相关参数 使用示例 | ✗ |
embedding | 从文件加载文本数据评测Embedding模型 支持Line-by-line(TXT)或JSONL格式(含text字段) | ✓ (必需) |
random_embedding | 根据max-prompt-length和min-prompt-length随机生成query评测Embedding模型 必需指定tokenizer-path | ✗ |
embedding_batch | 批量发送文本数据评测Embedding模型 从文件加载数据 支持--extra-args '{"batch_size": 8}'设置批次大小 | ✓ (必需) |
random_embedding_batch | 批量发送根据max-prompt-length和min-prompt-length随机生成query数据评测Embedding模型 必需指定tokenizer-path 支持--extra-args '{"batch_size": 8}'设置批次大小 | ✗ |
rerank | 从文件加载Query-Document对评测Rerank模型 支持JSONL格式 (含query和documents字段) | ✓ (必需) |
random_rerank | 根据max-prompt-length和min-prompt-length随机生成query数据评测Rerank模型 必需指定tokenizer-path 支持--extra-args '{"num_documents": 10, "document_length_ratio": 5}'设置文档数量和相对query的长度倍数 | ✗ |
custom | 自定义数据集解析器 参考自定义数据集指南 | ✓ |
模型设置
| 参数 | 类型 | 说明 | 默认值 |
|---|
--tokenizer-path | str | 分词器权重路径 用于计算输入和输出的token数量 通常与模型权重在同一目录 | None |
--frequency-penalty | float | frequency_penalty值 | - |
--logprobs | bool | 是否返回对数概率 | - |
--max-tokens | int | 可以生成的最大token数量 | - |
--min-tokens | int | 生成的最少token数量 注意:并非所有模型服务都支持 对于vLLM>=0.8.1,需额外设置 --extra-args '{"ignore_eos": true}' | - |
--n-choices | int | 生成的补全选择数量 | - |
--seed | int | 随机种子 | None |
--stop | str | 停止生成的tokens | - |
--stop-token-ids | list[int] | 停止生成的token ID列表 | - |
--temperature | float | 采样温度 | 0 |
--top-p | float | top_p采样 | - |
--top-k | int | top_k采样 | - |
--extra-args | str | 额外传入请求体的参数 JSON字符串格式 示例:'{"ignore_eos": true}' | - |
--tokenize-prompt | bool | 在客户端将prompt tokenize为token ID列表,绕过服务端重新tokenize,通过/v1/completions直接发送 | False |
数据存储
| 参数 | 类型 | 说明 | 默认值 |
|---|
--visualizer | str | 可视化工具 可选:wandb、swanlab、clearml 设置后指标将保存到指定工具 | None |
--enable-progress-tracker | bool | 是否开启进度追踪,将层级压测进度实时写入progress.json,可通过服务接口查询 | False |
--wandb-api-key | str | wandb API密钥 已废弃,请使用--visualizer wandb | - |
--swanlab-api-key | str | swanlab API密钥 已废弃,请使用--visualizer swanlab | - |
--outputs-dir | str | 输出文件路径 | ./outputs |
--no-timestamp | bool | 输出目录不包含时间戳 | False |
其他参数
| 参数 | 类型 | 说明 | 默认值 |
|---|
--db-commit-interval | int | 在写入SQLite数据库前缓冲的行数 | 1000 |
--queue-size-multiplier | int | 请求队列的最大大小 计算方式:parallel * multiplier | 5 |
--in-flight-task-multiplier | int | 最大调度任务数 计算方式:parallel * multiplier | 2 |