https://github.com/nazdridoy/kokoro-tts
https://zhuanlan.zhihu.com/p/18450040389

Kokoro TTS:支持多语言的轻量级TTS(文本转语音)模型
在人工智能语音合成技术快速发展的今天,Kokoro TTS 以其轻量级设计和高效性能脱颖而出。作为一个仅有82M参数的文本转语音(TTS)模型,Kokoro 在 TTS Spaces Arena 中击败了许多参数规模更大的竞争对手,成为语音合成领域的一颗新星。本文将详细介绍 Kokoro TTS 的技术特点、安装与使用方法及待优化方向。
Kokoro TTS 的技术特点
模型架构与参数规模
Kokoro TTS 基于 StyleTTS 2 架构,其参数规模仅为82M,远低于许多主流 TTS 模型(如 XTTS v2 的467M 参数和 MetaVoice 的1.2B 参数),但在单声道设置下表现卓越。

支持的语音与语言
Kokoro 最新版(0.23)支持多语言支持与声音克隆,包括:中、英、法、日、韩。每种语言支持多种音色以及男、女声,每种语音包都经过专业调校,确保音质清晰自然。英语支持美国英语和英国英语,并提供了10种独特的语音包,包括男声和女声(如 af_bella、af_sarah、am_adam 等)。
不过还不支持中文或韩文中与英语混合的情况。
性能优势与创新点
Kokoro 的训练数据量不到100小时,远低于其他模型(如 XTTS v2 的10,000小时),但其在 TTS Spaces Arena 中排名第一,证明了其在参数效率上的优势。此外,Kokoro 采用 espeak-ng 进行字形到音素(g2p)转换,进一步提升了语音合成的自然度。
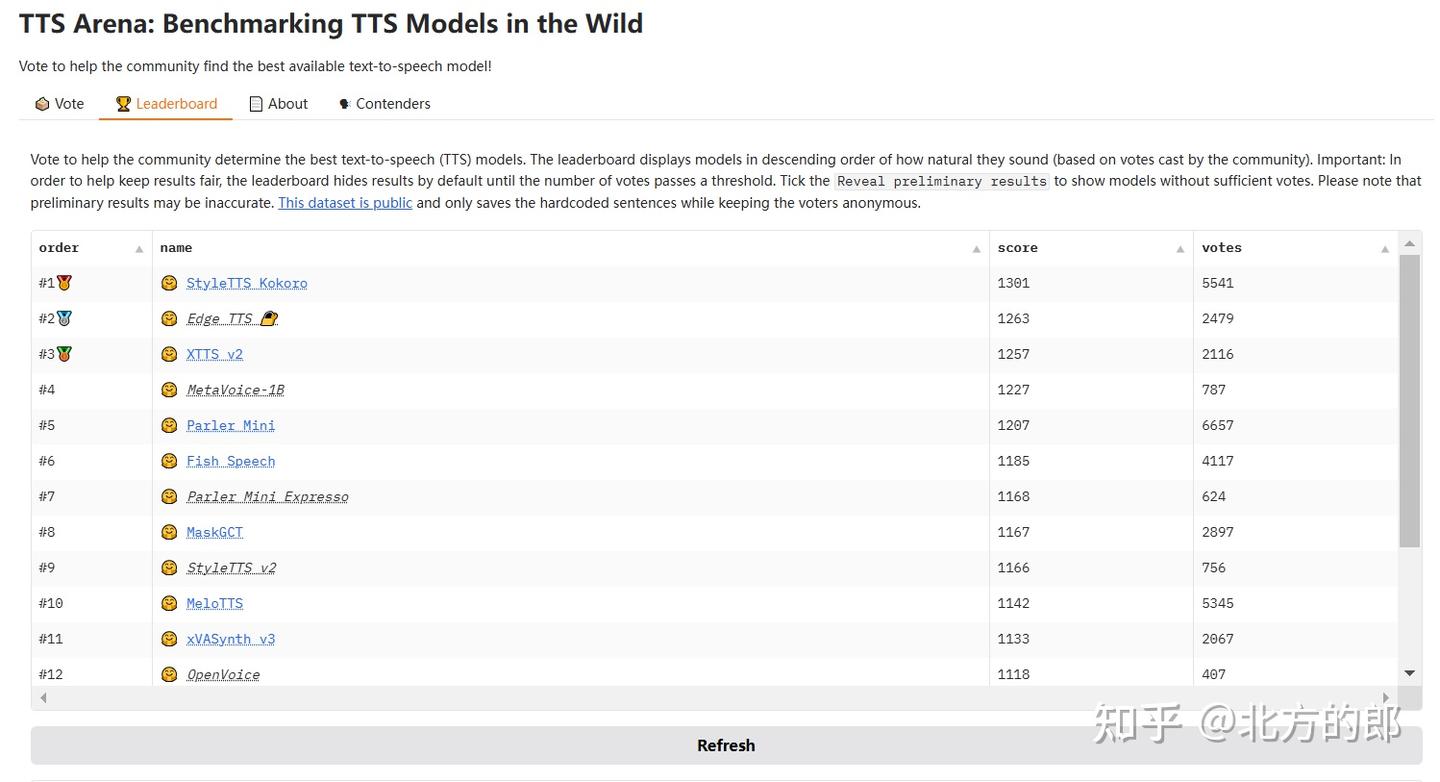
在TTS Arena上优势明显:https://huggingface.co/spaces/Pendrokar/TTS-Spaces-Arena
安装与使用指南
本地部署步骤
模型地址:https://huggingface.co/hexgrad/Kokoro-82M
以下步骤为notebook中使用
# 1️⃣ Install dependencies silently
!git lfs install
!git clone https://huggingface.co/hexgrad/Kokoro-82M
%cd Kokoro-82M
!apt-get -qq -y install espeak-ng > /dev/null 2>&1
!pip install -q phonemizer torch transformers scipy munch
# 2️⃣ Build the model and load the default voicepack
from models import build_model
import torch
device = 'cuda' if torch.cuda.is_available() else 'cpu'
MODEL = build_model('kokoro-v0_19.pth', device)
VOICE_NAME = [
'af', # Default voice is a 50-50 mix of Bella & Sarah
'af_bella', 'af_sarah', 'am_adam', 'am_michael',
'bf_emma', 'bf_isabella', 'bm_george', 'bm_lewis',
'af_nicole', 'af_sky',
][0]
VOICEPACK = torch.load(f'voices/{VOICE_NAME}.pt', weights_only=True).to(device)
print(f'Loaded voice: {VOICE_NAME}')
# 3️⃣ Call generate, which returns 24khz audio and the phonemes used
from kokoro import generate
text = "How could I know? It's an unanswerable question. Like asking an unborn child if they'll lead a good life. They haven't even been born."
audio, out_ps = generate(MODEL, text, VOICEPACK, lang=VOICE_NAME[0])
# Language is determined by the first letter of the VOICE_NAME:
# 'a' => American English => en-us
# 'b' => British English => en-gb
# 4️⃣ Display the 24khz audio and print the output phonemes
from IPython.display import display, Audio
display(Audio(data=audio, rate=24000, autoplay=True))
print(out_ps)API 接口与 Docker 化部署
Kokoro-FastAPI 是一个基于 Docker 的 FastAPI 封装,支持 NVIDIA GPU 加速和队列处理功能。用户可以通过 API 接口发送文本转语音请求,并获取高质量的语音输出。(Kokoro出来也没有多久,Kokoro-FastAPI就出来了,你就说现在开源软件发展多快吧)
Kokoro-FastAPI地址:https://github.com/remsky/Kokoro-FastAPI
在线体验与资源获取
用户可以通过 Hugging Face 平台访问 Kokoro 的在线演示,并下载模型权重和相关资源。
在线试用地址:
https://huggingface.co/spaces/hexgrad/Kokoro-TTS
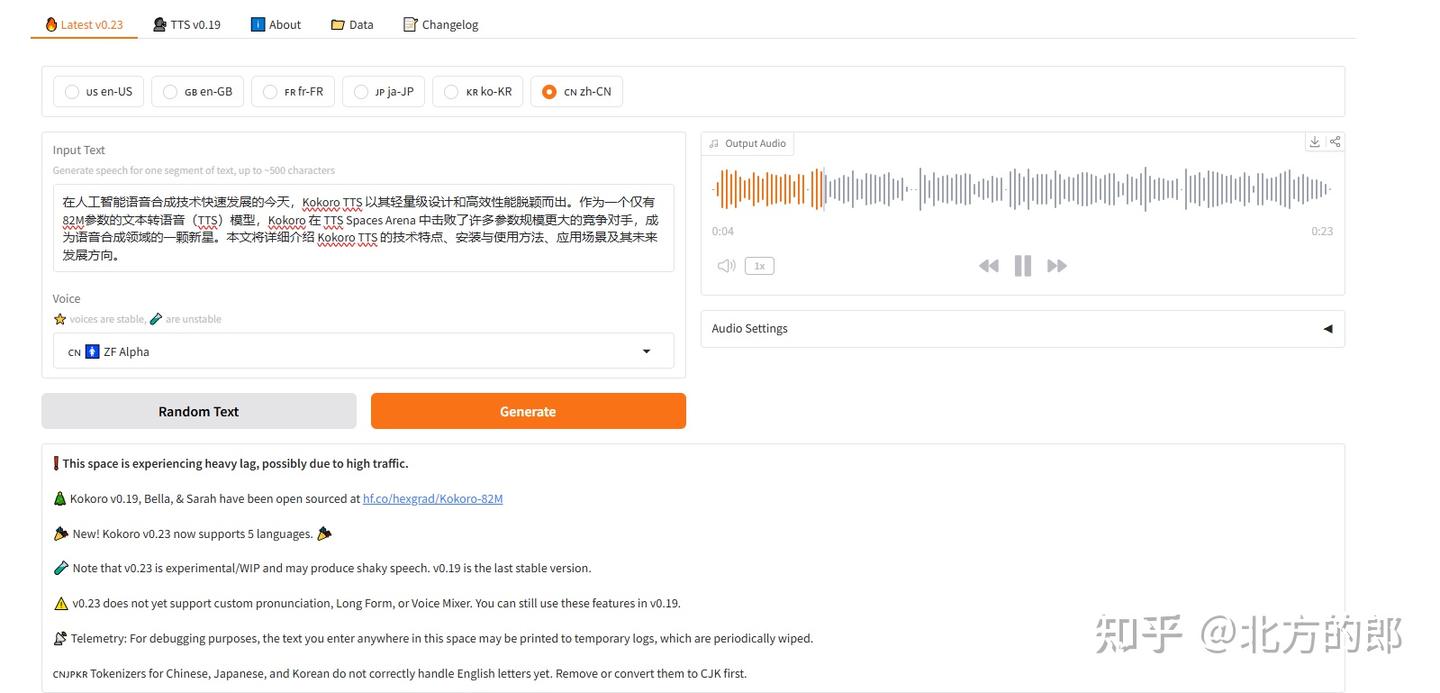
问题与挑战
可能是因为Kokoro TTS这个版本(0.23)刚支持中文的原因,现在Kokoro TTS中文速度很快,不过效果相对一般。而且中文分词器目前还不能正确处理英文字母。
我今天测试让Kokoro TTS生成中英文、数字混合内容,发现英文和数字都不能很好的生成。Kokoro TTS现在发展很快,未来应该会有提升,让我们拭目以待吧。
结论
Kokoro TTS 以其轻量级设计和高效性能,为语音合成领域带来了新的可能性。无论是开发者还是普通用户,都可以通过其开源特性和丰富的语音包,轻松实现高质量的文本转语音功能。随着技术的不断演进,Kokoro 有望在更多应用场景中发挥重要作用。